1 语义分割
语义分割(Semantic Segmentation)
语义分割的目标是将图像中的每个像素分割成不同的类别,但不区分同一类别中的不同实例。它只关心图像中的不同物体类别,而不关心它们是否属于不同的实例。
语义分割通常用于识别图像中的不同物体类别,如图像分割、图像分析、医学图像分析等。
1.1 思路1 滑动窗口
语义分割思路:滑动窗口
首先,选择一个固定大小的窗口(通常是正方形或矩形),然后将该窗口从图像的左上角开始滑动,按照一定的步长(通常是像素数)在图像上进行滑动。这将生成一系列重叠的图像窗口。
对于每个滑动窗口,从窗口中提取特征。然后对这个窗口做分类
这种方法可以工作,但效率太低。重叠区域特征反复被计算
因而更多采用思路2
1.2 思路2 全卷积网络
采用全卷积网络 也就是用全部都是多层的全卷积
这是怎么思考的呢?之前我们是给一整张图像做分类,而我们现在是给图像的每一个像素做分类
如果我最后一个卷积层输出的是(H×W×C)
H,W是图像的宽高,C是可能的分类的类别数
这样的话每一个像素点被映射为C维的向量,而我的标答也做成(H×W×C) 这样的话输出和标记之间就可以做损失函数运算了
但是有又有一个问题,就是我们中间 一直保持着原图的像素尺寸,中间计算量会很大,所以我们考虑通过先减小像素尺寸(下采样),再增大像素尺寸(上采样)
把特征图变小其实不难 如池化层,卷积层增大步长等
把特征图变大我们其实并没有学过
这里运用很多的是 转置卷积操作
特别方式
可学习的上采样:转置卷积
首先我们需要知道卷积操作是可以写作矩阵相乘的,只有这样我们才能实现并行运算,极大的加快运算速度
具体我们看这样一个二维的例子
输入图像 I(3x3的矩阵):
1 | I = | 1 2 3 | |
卷积核 K1(2x2的矩阵):
1 | K1 = | a0 b0 | |
我们希望将输入图像 I 与卷积核 K 进行卷积操作。
如果按照我们之前的卷积从左上角开始滑动,那么每一次运算必须等上一次运算完
而实际上我们可以把图像I写成这样一个矩阵
1 | I_expanded = | 1 2 4 5 | |
这是什么意思呢?就是把卷积核要运算的第一个方格(左上角的四个元素)里的元素展平放在第一行
要运算的第二个方格(右上角的四个元素)里的元素展平放在第二行
要运算的第三个方格(左下角的四个元素)里的元素展平放在第三行
要运算的第四个方格(右下角的四个元素)里的元素展平放在第四行
展开卷积核 K1:将2x2的卷积核 K 按照大小展开成一个列向量。
1 | K1_expanded = [a0 |
这样的话,将展开后的输入图像矩阵 I_expanded 与展开后的卷积核 K_expanded 进行矩阵相乘,得到卷积结果。
卷积前大小 (3×3)展开矩阵是(4×4)
卷积后大小(2×2)展开后是(4×1)
那么我们怎么把卷积后的这个大小恢复成原来的大小呢
得到的结果(4×1)乘 卷积核转置(1×4) =(4×4)
这也是为什么称之为转置卷积
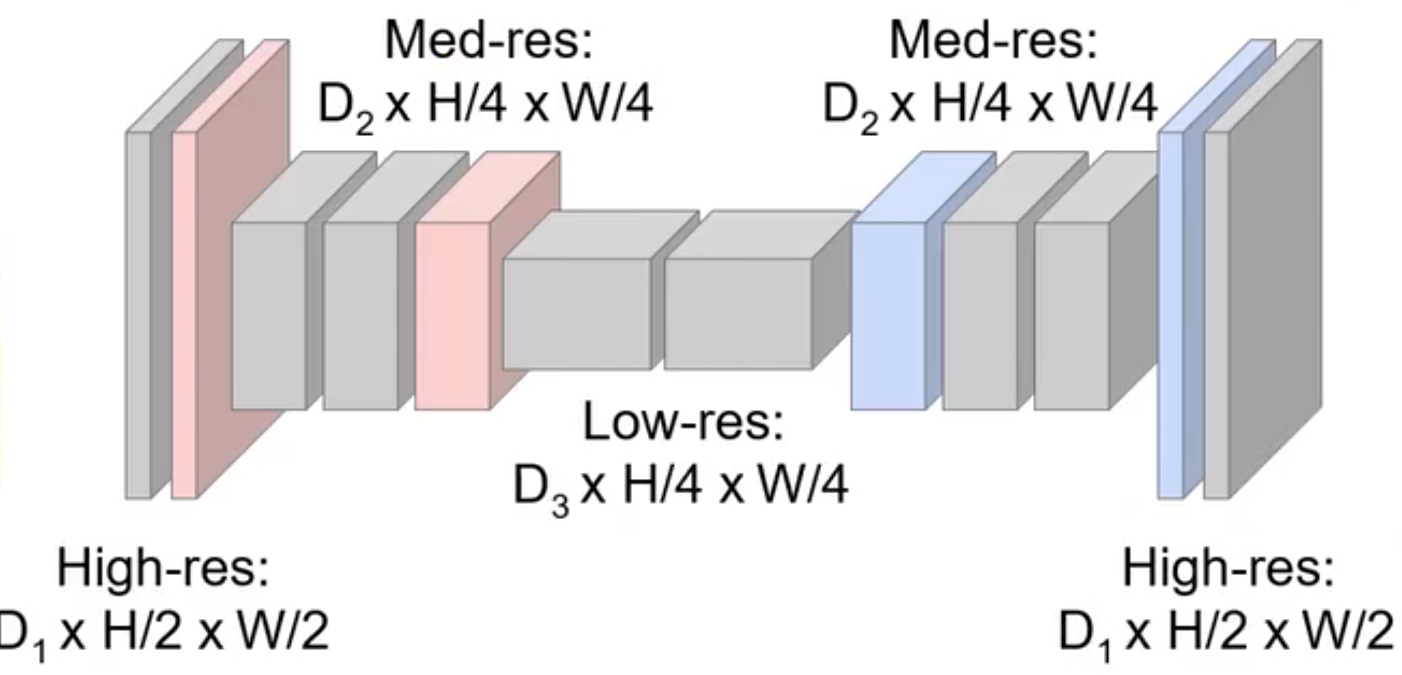
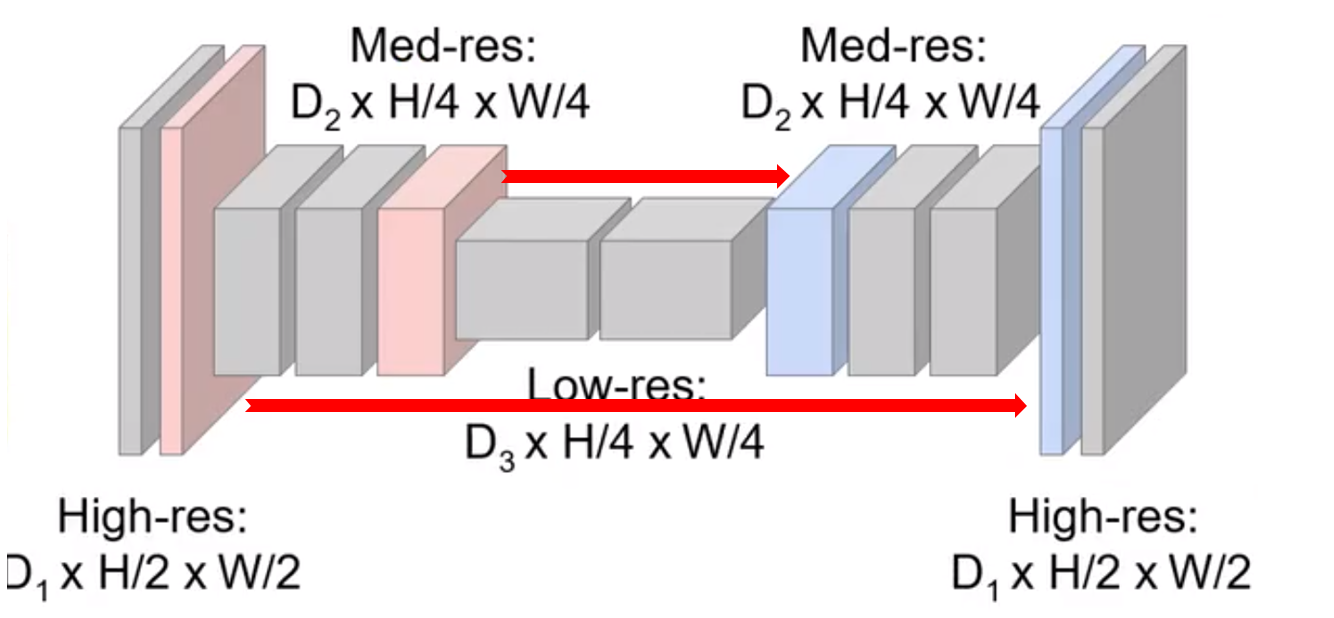
现在更多还使用一类叫做Unet
是在刚刚讲的基础上的改进
就是通过连接两个相同尺寸的把前面层的信息拼接到后面的层的信息,使得不同分辨率的语义(无论是高层还是底层)的信息都可以捕捉
2 代码实现
我们这次直接采用预训练模型来搭建这个网络
(1)对于下采样部分采用ReNet的预训练模型
Resnet会把输入图片的宽高缩为原来的1/32,通道数变为512
假设输入图片宽高 320,480,所以中间输出的宽高变为10,15
(2)对于上采样部分采用转置卷积网络
首先通过1×1卷积层把通道数变为分类总数,例子中是20
然后再经过转置卷积改变特征图尺寸,要把它扩大32倍,那么步长就是s=32
卷积核尺寸=2s=64
填充=s/2=16
上面这一套卷积核参数设置就可以把它扩大32倍
1 | import os |
输出
1 | torch.Size([1, 512, 10, 15]) |
可验证,中间输出的宽高变为10,15
最后输出恢复原始图像宽高,通道数变为分类总数20
3 实例分割
实例分割(Instance Segmentation)
实例分割的主要目标是将图像中的每个对象实例分割成不同的区域,并为每个区域分配一个唯一的标识符。这意味着它不仅可以识别不同类别的对象,还可以区分同一类别中的不同实例,如图像中的多个人或多辆车。
实例分割通常在需要区分不同对象实例的场景中使用,如自动驾驶中的行人检测和跟踪、人物姿势估计等。
以下是一些重要的深度学习方法和架构,用于实例分割任务:
- Mask R-CNN:Mask R-CNN是一种基于Faster R-CNN的扩展,它通过添加额外的分割分支来实现实例分割。除了目标的边界框,Mask R-CNN还生成了每个对象实例的像素级掩码,从而提供了准确的分割结果。这使得 Mask R-CNN 成为实例分割任务的流行选择。
- Panoptic Segmentation:Panoptic分割是一种将语义分割和实例分割结合起来的任务,旨在将图像中的每个像素分为具有语义标签的物体类别或属于特定对象实例。Panoptic分割方法通常使用深度学习模型来实现,如Panoptic FPN等。
- DETR(Data Efficient Transformer):DETR 是一种新兴的实例分割方法,它基于Transformer架构,将实例分割任务转化为一个端到端的目标检测和分割问题。DETR 通过注意力机制来对目标的位置和像素级别的分割进行联合建模,取得了卓越的性能。
- PointRend:PointRend 是一种用于提高实例分割性能的方法,特别关注于处理分割边缘区域的细节。它通过逐像素的自适应池化操作来改进掩码的质量,从而提高分割精度。
- SOLO(Segmenting Objects by Locations):SOLO 是一种基于实例的分割方法,它使用了网格级别的特征图和目标特定的位置信息,以实现物体实例的分割。SOLO 将实例分割任务与目标检测分割任务相结合。
- Embedding-based方法:一些实例分割方法采用嵌入向量来表示每个像素,然后使用聚类技术或后处理步骤来将像素分配到不同的实例。这些方法在性能和效率方面取得了良好的平衡。



