1 目标检测
目标检测的重要任务是
- 目标定位:目标检测的首要任务是确定图像中对象的位置,通常使用边界框(Bounding Box)来描述目标的位置。边界框由一对坐标表示,通常是左上角和右下角的坐标。
- 目标识别:目标检测不仅要定位目标,还要识别目标的类别或类别标签。这通常涉及将检测到的对象与已知的类别进行比较,从而确定它是什么物体。
所以目标检测可以通俗理解为分类+定位
我不仅要告诉你什么类别,还要告诉你在哪儿
在这个任务中,我们用边界框,来定位我们的物体
边界框的位置表示有两种
第一种是边框的坐上,右下的点的坐标点x1,y1 x2,y2
第二种是边框的中间点坐标,和宽高
两种方式都可以唯一确定图片上的边框,并且可以相互转换
1.1 单目标检测
即图片中只有一个要检测的物体,这个难度相对来说小一些
直观可以想到一种方式
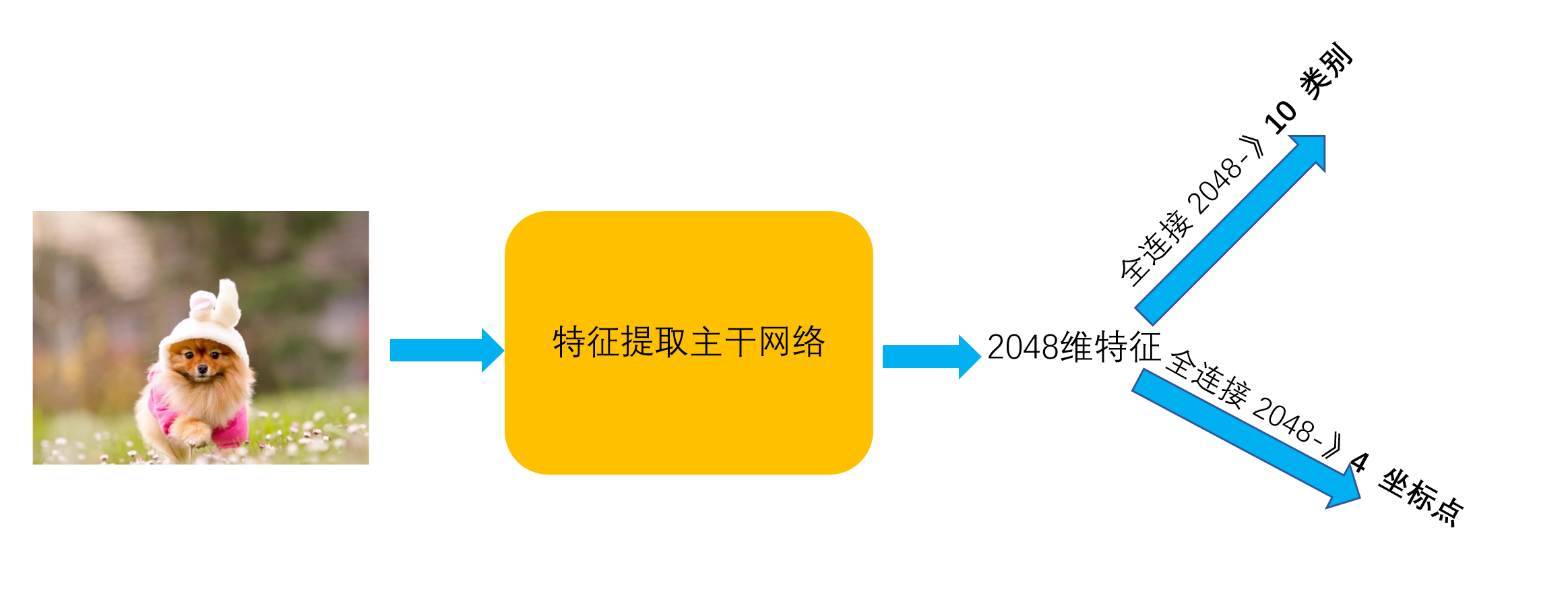
首先拿一个卷积网络提取特征
再利用提取到的特征(假如提取到的特征是2048)一方面可以接一个全连接层做分类(比如2048到10类),另一方面可以接全连接层做坐标点的回归(比如2048到4个坐标点)
这样需要两个损失函数,一个损失函数降低分类错误率,另一个损失函数降低回归错误率,我们称这样的网络叫做多任务多损失网络
对于这样的任务
一般可以多阶段训练
1 先训练分类分支
2 再在分类分支训练好的基础上训练坐标点回归
3 最后一步将两个合并到一起训练
1.2 多目标检测
图片中可能有多个要检测的物体,这个难度就更大了
物体的个数是未知的,我们不能像单目标检测那样只回归一个坐标点,回归的坐标点个数是未知的!!天啊该怎么呢
所以研究者们做了如下一些尝试
3.2.1 阶段一 单像素点采样目标检测
既然直接回归不行,那么我们可以先产生很多的边界框(术语叫锚框),让网络对这些边界框 锚框一个一个做分类,并预测它距离真实边框的偏移量!
最开始大伙儿尝试直接对于每个像素点给出不同尺寸的锚框
当生成足够多的锚框的时候,大力出奇迹,总会有框几乎把我们的目标框住的
这时候对于每个区域进行分类判断,一张图片可能会产生几十万上百万张图片,然后让网络进行分类
直观感受 是有点鲁莽!!!密集恐惧症颤抖
实际也证明这种方式的运算量巨大,但他是可行的方式
训练阶段
我们把每一个锚框看作一个训练样本
这个训练样本需要两个标记,一是类别(一般就分配给与它最近边框的类别即可),二是与它最近的真实边框的偏移量
模型对于每一个框需要预测它的类别,与最近的真实边框的偏移量
预测阶段
首先为图像生成多个锚框
利用模型为这些锚框一 一预测类别和偏移量
有一个可能的问题,我们生成了多个相似的具有明显重叠的锚框
采用非极大值抑制来合并属于同一目标的相似的边界框
(1)首先,根据每个候选边界框的得分(通常是模型预测的物体存在概率或置信度分数)对所有候选边界框进行降序排序,得分较高的边界框排在前面。
(2)选择得分最高的边界框,并将其添加到最终的筛选结果中。这个边界框通常被认为是最有可能包含真实目标的边界框。
(3)于剩余的候选边界框,计算它们与已选择的高分边界框的重叠区域(通常使用IoU,Intersection over Union来衡量)。IoU是两个边界框重叠区域与它们的联合区域的比例。
(4)剔除重叠边界框:如果某个候选边界框与已选择的高分边界框具有高于预定阈值的IoU值(也就意味着和我们得分最高的边界重叠过高),则将该候选边界框从列表中移除
(5)重复步骤:重复步骤2到步骤4,直到没有更多的候选边界框需要处理。
(6)输出结果:NMS会输出一组经过非极大值抑制筛选的边界框
可以做这样一个比喻来通俗理解这件事情
想象你是一名宝藏猎人,你有一块地图上标有可能埋有宝藏的若干区域。你的任务是找到最有可能埋有宝藏的区域,同时避免走重复的路线,因为这不会增加你找到宝藏的机会。
- 得分排序:每个区域都有一个分数,表示它有多大的可能性埋有宝藏。你首先查看地图上所有区域的分数,将得分最高的区域放在列表的最前面,就像把最有希望的区域标记在地图上。
- 选择高分区域:你首先前往得分最高的区域,因为那里找到宝藏的可能性最大。
- 计算重叠区域:当你到达一个区域后,你会注意到一些其他区域可能与你当前所在的区域有很大的重叠。这就像你走到了一个区域,但可能有其他猎人也在附近搜索。
- 剔除重叠区域:为了避免重复工作,你会检查其他猎人所在的区域,如果它们与你当前的区域有很大的重叠(重复搜索的可能性高),你会决定不再前往这些区域,而是继续前往下一个可能性很高的区域。
- 重复步骤:你会不断重复前往得分最高的区域、计算重叠区域和剔除重叠区域的步骤,直到你认为没有更值得前往的高分区域为止。
- 输出结果:最终,你的努力会得到一组标记为最有可能埋有宝藏的区域,而且你不会重复浪费时间去搜索高度重叠的区域。
3.2.2 阶段二 多像素点采样目标检测
单像素点采样直接对于所有像素点为中心给出不同尺寸的锚框,运算量巨大
那么我们可不可以降低一下这个运输量呢?
当然可以啦
我们以一小部分像素为中心生成不同锚框
比如2×2像素,比如4×4像素
这样就可以降低我们的锚框量啦
3.2.3 阶段三 RNN
但是即便如此,锚框量依然巨大
那么我们可不可以进一步减少锚框量呢,可以的
我们可以采用某些算法,给出建议区域,即找出所有潜在可能包含目标的区域
这便是R-CNN系列
R-CNN
1 利用区域建议方法selective search产生的感兴趣区域,大约2000个候选区域(或称为候选框),这些区域被认为可能包含目标物体。
2 对于每个候选区域,R-CNN将其缩放裁剪出来,并通过一个预训练的卷积神经网络(通常是AlexNet)提取特征。这些候选区域在CNN中前向传播,生成固定长度的特征向量。
3 特征向量被送入一个独立的支持向量机(SVM)分类器,每个SVM分类器用于识别特定类别的目标物体。这意味着为每个可能的目标类别都训练一个二元分类器,以判断特定候选区域是否包含属于该类别的物体。
4 此外,R-CNN还包括一个边界框回归器,用于微调候选区域的边界框,以更准确地定位目标物体。
5 最后,为了去除重叠和冗余的检测结果,使用非极大值抑制(NMS)来选择最终的检测边界框。
R-CNN可以有着更高的精度,处理的锚框也少了,但是它产生感兴趣区域也很耗时
总结来看他的缺点
- 训练和推理速度慢,因为每个候选区域都要进行独立的前向传播和分类。
- 需要大量的存储空间,因为要保存每个候选区域的特征向量和分类器参数。
- 不够端到端,训练过程相对复杂。
Fast R-CNN
Fast R-CNN看名字就可以知道哈哈哈哈是R-CNN的改进,让他变得更快,同时变得端到端
1 首先利用卷积网络进行特征提取
2 提取到的特征图再做感兴趣区域建议!而特征图的区域是可以和原图一一映射的
3 再对取出来的区域做裁剪缩放(Rol Align 双线性插值),然后利用全连接层输出每个感兴趣区域的特征进行分类或回归
4 使用非极大值抑制(NMS)来选择最终的检测边界框。
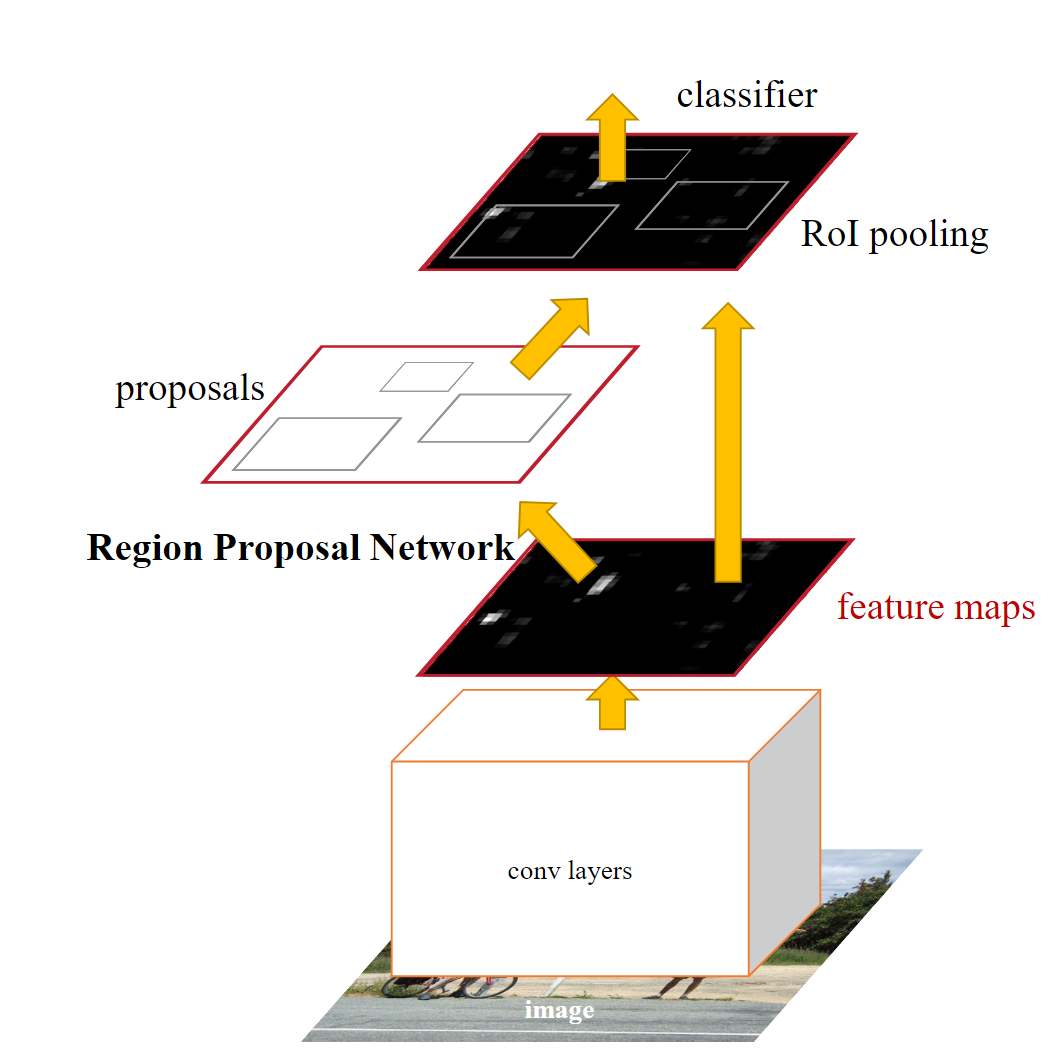
Faster R-CNN
与R-CNN不同,Fast R-CNN不再使用选择性搜索等传统方法生成大量候选区域。相反,它引入了一种叫做”候选区域提取网络(Region Proposal Network,RPN)”的网络模块,用于生成高质量的候选区域。提高了效率
1 首先利用卷积网络进行特征提取
2 提取到的特征图利用候选区域提取网络获得感兴趣区域!而特征图的区域是可以和原图一一映射的
候选区域提取网络需要进行二分类 是目标还是背景
3 再对取出来的区域做裁剪缩放(Rol Align 双线性插值),然后利用全连接层输出每个感兴趣区域的特征进行分类或回归
4 使用非极大值抑制(NMS)来选择最终的检测边界框。
3.2.4 阶段四 一阶段的目标检测 Yolo/SSD
Yolo
YOLO采用单一的卷积神经网络来同时处理目标检测和分类任务。与传统的两阶段目标检测方法不同(如R-CNN系列),YOLO将目标检测任务转化为回归问题,一次性输出所有检测框的位置和类别信息。
不用区域建议网络了,直接把图片分成7×7,每个网格单元负责检测图像中的物体,产生一个或多个候选框。
每个网格单元预测多个候选框(通常是B个,如2或3个)。每个候选框由5个参数定义:中心坐标(x, y)、宽度(w)、高度(h)以及物体存在概率(objectness score)。这些参数用于定义每个候选框的位置和是否包含物体。
每个网格单元还预测C个类别的概率分数,用于表示物体属于每个类别的可能性。这些类别概率分数与每个候选框关联。
SSD
SSD和之前工作主要区别是
SSD引入了一组称为Anchor框的预定义边界框。每个Anchor框与特定位置和尺度的特征图单元相对应。这些Anchor框用于尝试捕获不同尺寸和比例的物体。
结论
Faster R-CNN速度偏慢,但精度高
SSD速度快,精度高
主干网络越宽,深度越深对性能帮助越大


