之前我们学习了线性分类器
深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解_Qodi的博客-CSDN博客
全连接神经网络(又叫多层感知机)和我们的线性分类器区别
(1)线性分类器就只有一个线性变化
而全连接神经网络利用激活函数(非线性操作),级联多个变换
(2)线性分类器只能解决线性可分问题,而我们的全连接神经网络由于加入了非线性操作激活函数,可以解决线性不可分问题。
激活函数是神经网络中非常重要的组成部分,与此类似,人脑中的神经元也具有类似的激活功能。深度学习受启发于脑科学,他们有如下相似点相似点:
- 非线性:激活函数和人脑神经元都是非线性的。这是因为如果神经元都是线性的,则整个神经网络只能表示线性函数,无法应对复杂的非线性问题。
- 阈值:激活函数和人脑神经元都具有阈值。当输入值超过一定阈值时,神经元才会被激活,并产生输出。这种阈值的设置可以使神经网络更加适应不同类型的数据分布。
下面我们来详细看一下内容
1 多层感知机(全连接神经网络)
1.1 表示
多层感知器又叫做全连接神经网络
比如 两层全连接神经网络图像表示:
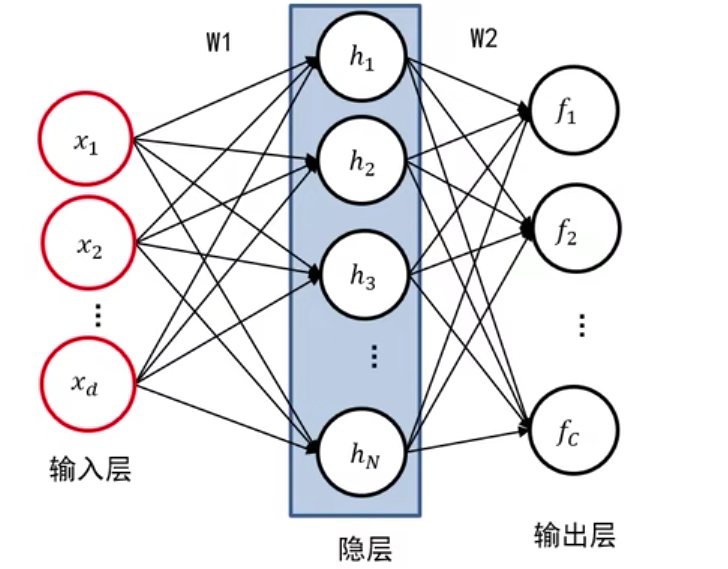
两层全连接网络 数学表达式:
$f=W_2max(0,W_1x+b_1)+b_2$
1.2 基本概念
全连接神经网路的概念
输入层
输入层是神经网络的第一层,它接收外部输入并将其转换为神经网络能够理解的形式。例如,对于图像识别的任务,输入层通常将图像像素作为输入。
隐层
隐层是输入层和输出层之间的中间层,它的作用是将输入层传递来的信息进行加工处理,并将处理后的信息传递给输出层。隐层可以有一个或多个,每个隐层包含多个神经元。
输出层
输出层是神经网络的最后一层,它接收隐层传递过来的信息,并将处理后的结果输出为最终的预测结果。例如,在图像识别任务中,输出层可以输出对应的物体类别。
全连接
某一层的每一个神经元要和前层的所有神经元相连,所以叫做全连接
$f=W_2max(0,W_1x+b_1)+b_2$
层数
除了输入层以外 有几层就叫几层神经网络(包括所有隐层和输出层)
如上面图就是两层的神经网络
全连接神经网路由线性部分和非线性部分多层级联而成
1.3 必要组成—激活函数
我们说激活函数的作用就是非线性操作,那么常见的激活函数有哪些呢?
1 Sigmoid函数
$\frac{1}{1+e^{-x}}$
特点
- 它的输出值在0和1之间
- 不是中心对称的
2 tanh函数
$\frac{e^x-e^{-x}}{e^x+e^{-x}}$
双曲正切函数
- 让数值变到-1和+1之间
- 是中心对称的
以上两种函数都容易导致梯度消失问题(稍后讲到)
当代网络深度较深,梯度消失问题容易发生,所以更多采用如下函数
3 ReLU 函数
$max(0,x)$
ReLU函数在输入大于0时返回输入值,否则返回0。它的优势是计算速度快,不会有梯度消失问题;缺点是在输入小于0时,梯度为0,导致神经元无法更新。
4 leaky ReLU 函数
$max(ax,x)$
Leaky ReLU函数在输入小于0时返回一个非零值,可以解决ReLU函数的问题。
这些激活函数都有各自的优缺点
1.4 网络结构设计
综上我们学到的知识,我们实际的网络设计实际就是要自行解决如下两个问题
1、用不用隐藏,用一个或者几个隐层 (深度设计)
2、每个隐层设置多少个神经元比较合适 (宽度设计)
神经元个数越多,分界面就越复杂,分类能力越强,但容易出现过拟合
2 损失函数
在线性分类器那一节里讲到模型会给不同类别分数,但是直接的分数不能代表分类概率,而且有时候会出现打负分的情况
分类概率总和必须为1
所以我们进行Softmax操作
2.1 SOFTMAX操作
而Softmax函数可以将每个神经元的输出值映射到0和1之间,并且所有输出的和等于1,可以表示每个分类的概率。
操作过程
得到一组分数f1,f2……fn
1 取指数
$t_i=e^{f_i}$
2 归一化
$p_i=\frac{t_i}{\sum{t}}$
假设我们有一个三分类问题,我们需要将神经网络的输出值转换成对应的分类概率。输出层有三个神经元,分别对应三个类别,输出值为:
$[0.5, 1.2, -0.3]$
我们可以使用Softmax函数将每个神经元的输出值转换为对应的概率。首先,计算每个神经元的指数函数值:
$[e^{0.5}, e^{1.2}, e^{-0.3}]$
然后,将指数函数值除以所有函数值的和,得到每个神经元对应的概率:
$[0.244, 0.665, 0.091]$
这意味着第一个类别的概率为0.244,第二个类别的概率为0.665,第三个类别的概率为0.091。可以看出,Softmax函数对每个神经元的输出值进行了归一化,并将它们转换为对应的概率,从而方便我们进行多分类问题的预测和训练。
在线性分类器那一节的损失函数——支撑向量能力比较的有限,今天介绍的交叉熵损失函数应用更广
交叉熵损失函数的基本思想是,用模型的输出概率分布与实际标签的分布之间的差异来衡量模型的损失程度,从而调整模型的参数。
2.2 交叉熵损失函数
在介绍交叉熵之前,需要先了解几个概念,其中p和q是两个不同的分布
假设存在两个概率分布 P,Q 注意下面的log是以e为底
熵: $H(p)=-\sum_xp(x)logp(x)$
熵是信息论中用于衡量随机变量不确定性的指标,它表示一个随机变量的平均信息量。熵越大,表示随机变量的不确定性越大,即信息量越大。例如$[0 , 0 ,1]$这个分布没啥信息量,代入公式计算为0 因为他的不确定度很小
而对于分布[0.3,0.3.0.4]这个分布不确定性比较大,熵值就很大了
相对熵:$KL(p||q)=-\sum_xp(x)log\frac{q(x)}{p(x)}$
相对熵,也叫KL散度用来度量两个分布的不相似性(这里不叫做距离,是因为距离的话P到q和q到p的距离应该是一样的)而这里的话有可能不一样
如果两个分布一样,则相对熵为0,如果两个分布差异越大,相对熵越大
比如分布P[0,0,1]为和分布Q为 [0.3,0.3,0.4] 的相对熵为0.39,说明他俩相差比较大
而分布P为[0,0,1]和分布Q为 [0,0.1,0.9]相对熵0.04.说明他俩相差较小
实际中用到更多的是交叉熵
交叉熵: $H(p,q)=-\sum_xp(x)logq(x)$
因为三者存在这样一个关系
$H(p,q)=H(p)+KL(p||q)$
而如果P分布是标答,分布是独热码的形式,那么它的H(p) 就等于0 ,这样的话
$H(p,q)=KL(p||q)$
我们就可以用交叉熵来代表相对熵了,计算更简单
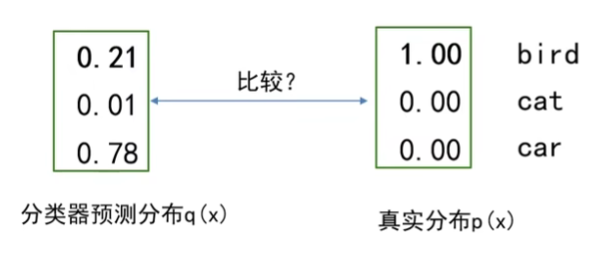
计算交叉熵如下
$1log(0.21)+0log(0.01)+0*log(0.78)=log(0.21)$
最后记得取负数 也就是$-log(0.21)$
我们发现为零的项完全不用计算
所以实际上 $L_i=-log(q_j)$ j为真实值类别
实际输出就是真实标签概率的负对数。
关于一些损失函数的比较,和交叉熵损失pytorch的代码具体实现,可以查看我之前的这篇博客
从原理到代码实践 | pytorch损失函数_Qodi的博客-CSDN博客
3 优化
3.1 求导计算过于复杂?
我们实际计算中,会发现原本的损失函数会十分复杂,因而我们该怎么办求导?方法就是采取计算图
利用计算图避免直接计算庞大的导数,将庞大的求导数化解为一个一个小的部分
计算图本质就是利用链式法则
计算图我也专门写了一篇博客,有代码的相关实现
pytorch的自动微分、计算图 | 代码解析_Qodi的博客-CSDN博客
3.2 链式法则导致的问题?
上述我们发现用计算图通过链式法则的方法可以很好得解决计算复杂的问题,但是我们发们发现这其中会有很多连乘,这样的情况下就可能会出现如下两个问题
梯度消失
本质是由于链式法则的乘法特性导致的
对于Sigmoid函数,tanh函数,由于导数很小,所以会导致反传的时候梯度消失,所以现在对于这种情况就是运用比较少了
Relu函数 ,对于大于0 的时候,梯度永远不会消失,而且计算很简单,所以应用比较多。但是对于小于零的情况不太好,
梯度爆炸
也是由链式法则导致的,某一点的梯度特别大
解决方案 梯度裁剪
梯度裁剪的基本思想是,设置一个梯度阈值clip_value,如果梯度的绝对值大于这个阈值,就将梯度进行缩放,使其绝对数等于阈值。
普通梯度下降算法可能会存在的问题
一个方向上变化迅速 而在另一个方向上变化缓慢!同时
- 依赖于学习率: 梯度下降算法的效果受到学习率的影响,如果学习率过大,会导致算法不收敛或者震荡;如果学习率过小,会导致算法收敛速度过慢。
- 可能会陷入局部最优解: 梯度下降算法的搜索方向只依赖于当前位置的梯度信息,因此可能会陷入局部最优解,无法找到全局最优解。
3.3 梯度下降算法的改进
3.3.1 动量法
动量法可以加快梯度下降的速度,同时也可以避免梯度下降过程中出现的震荡现象。
$w$代表参数 $\epsilon$学习率,反向回传计算梯度后得到梯度g
则传统梯度下降的参数更新表达式为:
传统梯度下降参数更新 $w=w-\epsilon g $
现在这个g变为动量v(t )
即动量法参数更新$w=w-v(t) $
v(t)就是我们说的动量
(1)第一步要计算动量,需要用到前一时刻的动量
$v(t)=u*v(t-1)+g$
u是一个超参数 动量系数 ,一般设为0.9
如果设置为0 则退化为标准小批量梯度下降算法
如果设置为1 ,即使g到了平坦区域依然停不下来
而如果u小于1的话,在g到了接近0 的情况下,v由于u的存在就会不断减小,让他到达一个较低平坦点
就好像摩擦系数一样,让他一点一点停下来。
v(t-1)是前一时刻的动量
具体来说,动量法在更新参数的过程中,不仅考虑当前的梯度,还考虑之前的梯度,从而使得更新方向更加稳定。
(2)然后v(t)代入梯度下降参数更新式
动量法还有什么效果?
避免到达局部最小点,鞍点停下来
举例:
假设我们要使用动量法来优化以下函数:
$f(x,y) = x^2 + 2y^2$
我们希望求出使得函数f(x,y)最小的点。首先,我们通过梯度计算出当前点的梯度,然后根据动量法的公式来更新参数。假设学习率为0.1,动量系数为0.9,我们可以按照以下步骤进行迭代:
- 初始化参数x=1,y=1,初始动量$v_x(t-1)=0,v_y(t-1)=0$
- 计算当前点的梯度g(x)=2x,g(y)=4y
- 根据动量法的公式来更新动量$v_x(t)=0.9v_x(t-1)+ 2x,v_y(t)=0.9v_y(t-1)+ 4y$
- 根据动量v(x)和v(y)来更新参数$x=x-0.1v_x(t),y=y-0.1v_y(t)$
- 重复第2-4步,直到收敛到最优点
3.3.2 自适应梯度方法
1 AdaGrad
和动量法思路不一样,分别改变学习率
1 区分哪个方向是震荡方向,哪个方向是平坦方向就可以了,在震荡方向减少步长,平坦方向增大步长
2 如何区分平坦还是震荡?
通过梯度幅度的平方较大的地方,梯度幅度平方较小的方向是平坦方向
$w$代表参数 $\epsilon$学习率,反向回传计算梯度后得到梯度g
则传统梯度下降的参数更新表达式为:
传统梯度下降参数更新 $w=w-\epsilon g $
动量法参数更新$w=w-v(t) $
而自适应的AdaGrad参数更新
$w=w-\frac{\epsilon}{\sqrt{r}+\delta}g$
其中 $ r=r+g*g$ 利用新得到的r来更新权值
当r 较小时 $\epsilon$ 就会被放大 整体学习率变大
当r 较大时 $\epsilon$ 就会被缩小 整体学习率变小
具体来说,Adagrad算法会对每一个参数维护一个历史梯度平方和的累加量,并将其用于调整学习率。在更新每一个参数时,Adagrad算法会根据历史梯度平方和对当前的梯度进行归一化,然后再乘以学习率。这样可以使得每个参数的学习率自适应地调整,更好地适应不同的数据集和模型。
根号r旁边加了一个小常数,避免除零
缺陷 r会不断累积 会让r变得很大,这时候就会导致无法起到调节作用
基于这个缺陷的改进算法RMSProp
2 RMSProp
上面讲到 自适应的AdaGrad参数更新
$w=w-\frac{\epsilon}{\sqrt{r}+\delta}g$
其中 $ r=r+g*g$
而对于自适应RMSProp参数更新
$w=w-\frac{\epsilon}{\sqrt{r}+\delta}g$
其中$ r=\rho r+(1-\rho)g*g$
加上一个衰减项,解决了上面的缺陷
具体是,当r变得较大的时候,后面部分就不起作用了
使得$r=\rho r$ 由于$\rho<0$ 所以r就会减小 不会无限制变大
3.3.1 Adam
同时使用动量和自适应梯度的方法

这里加了一个修正偏差 可以 极大减缓算法初期的冷启动问题
最开始启动的时候 梯度很小,更新很慢,所以要修正偏差
4.网络信息流通畅
为了使得训练正常进行
要正向反向信息流传递通畅,为此有一些技巧
4.1 权值初始化
初始化作用
- 避免梯度消失和梯度爆炸:在神经网络中,参数的初始化会影响到反向传播计算中梯度的大小,过小或过大的参数都会导致梯度消失或梯度爆炸的问题。通过合理的参数初始化,可以使得梯度的大小更加合适,防止出现梯度消失或梯度爆炸的情况,从而提高模型的稳定性和收敛速度。
- 加快网络收敛速度:合理的参数初始化可以使得神经网络在训练初期更快地收敛,从而提高模型的训练速度和效率。例如,我们可以使用Xavier初始化、He初始化等方法来初始化参数,从而提高模型的收敛速度。
- 提高模型泛化能力:合理的参数初始化可以使得神经网络更好地适应新的样本,从而提高模型的泛化能力。例如,对于卷积神经网络和循环神经网络,我们可以使用不同的参数初始化方法来提高模型的泛化能力和性能。
有效的初始化方法
正向信息流顺利,反向梯度流也顺利
Xavier初始化方法
Xavier初始化的主要思想是根据输入和输出神经元的数量来设置每个权重的初始值,使得这些权重的方差保持不变。
权值采样自N(0,1/N)的高斯分布
适合双曲正切和Sigmoid函数
但是不适合ReLu激活函数
ReLu函数适合下面的方法
He 初始化方法
权值采样自N(0,2/N)的高斯分布
当ReLU函数和Leakly ReLU函数方法
4.2 批归一化 Batch
调整权值分布使得输出与输入具有相同的分布
减去小批量均值除以小批量方差再输出
计算小批量均值
计算小批量方差
批归一化操作 在非线性激活之前,全连接层后
避免梯度消失
5 .对抗过拟合方法
5.1 随机失活 Dropout
随机使得某一层的神经元失活
为什么可以达到效果
- 解释一: 参数量减少
- 解释二: 鼓励权重分散
- 解释三: 可以看做模型集成
5.2 数据增强
过合理地对原始数据进行变换,增加训练集的样本数量,从而减少模型的过拟合风险。例如,对图像数据进行旋转、翻转、缩放等操作,对文本数据进行随机切割、替换等操作。
5.3 正则化
正则化是一种常用的缓解过拟合的方法,它通过在损失函数中增加正则项来惩罚模型的复杂度,从而减小模型的过拟合风险。常用的正则化方法包括L1正则化、L2正则化和弹性网络等。
5.4 批归一化
批归一化可以减少每一层输入的分布变化,从而使得网络更快地收敛,同时也可以作为一种正则化技术,减小模型的过拟合风险。
6 超参数优化方法
6.1 网格搜索法
网格搜索法是一种简单直观的超参数优化方法,它通过遍历超参数空间中所有可能的组合,来查找最佳的超参数组合。具体来说,网格搜索法首先需要定义超参数的取值范围,然后将每个超参数的取值范围离散化,生成一个超参数网格。然后遍历这个网格上的所有组合,依次评估每个组合的性能,最终找到最佳的超参数组合。
6.2 随机搜索法
随机搜索法是一种更加高效的超参数优化方法,它通过在超参数空间中随机采样,来查找最佳的超参数组合。具体来说,随机搜索法首先需要定义超参数的取值范围,然后在这个范围内随机采样若干组超参数组合,依次评估每个组合的性能。随机搜索法的优点是可以避免网格搜索法中的过拟合问题,同时对于超参数空间较大或维度较高的情况,随机搜索法更加高效。
可以先粗搜索,搜索间隔调大一些,选定区域后 再细搜索


